Utilize and Preserve Text- and Language-based Research Data
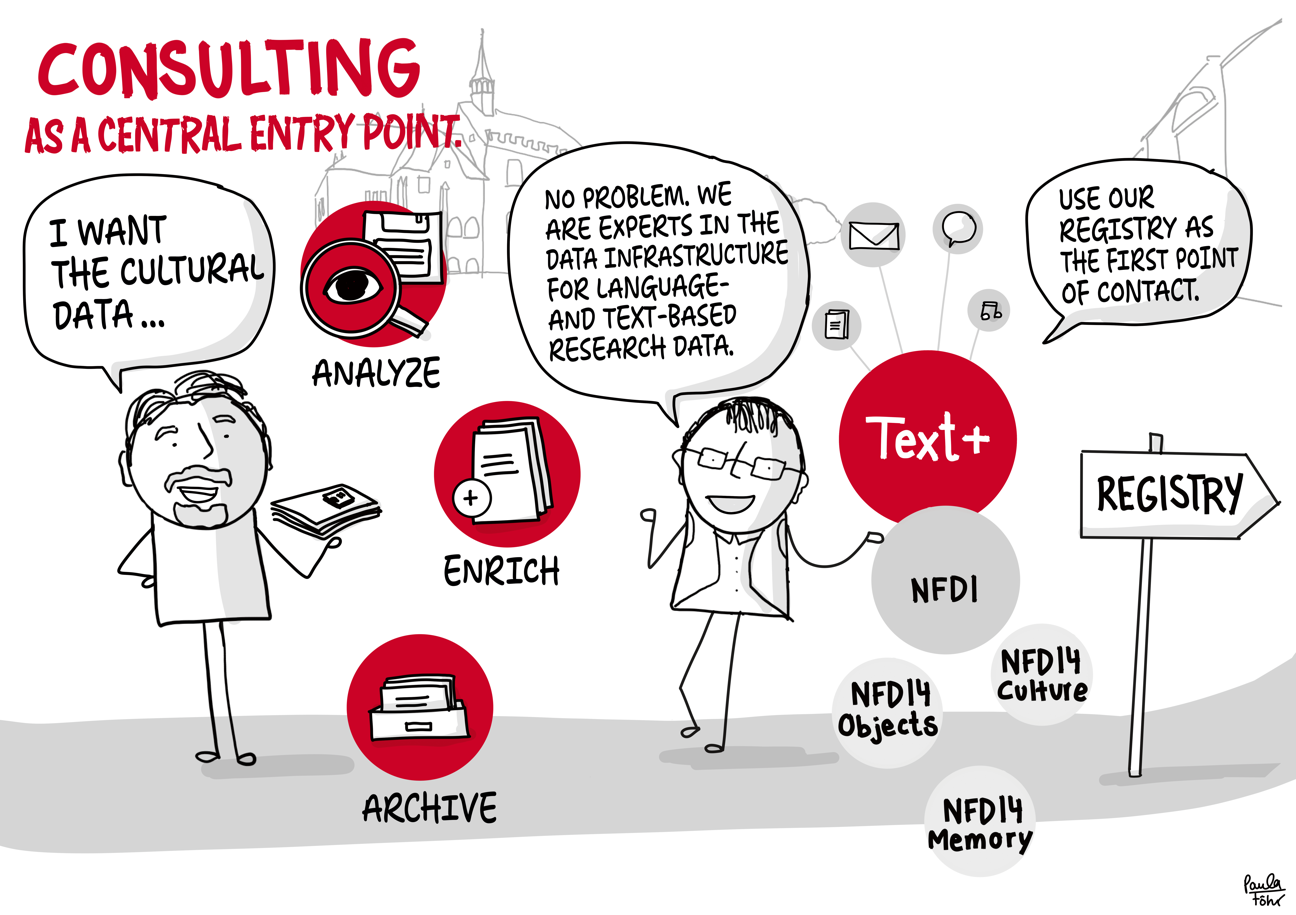
Text+ provides an extensive collection of text collections and corpora, editions and lexical resources for re-use as part of the NFDI. In addition to its own data and services, the service portfolio also includes the option of integrating and preserving research data from the community in the long term.
Text+ and the NFDI
As part of the National Research Data Infrastructure (NFDI), the DFG is funding a total of 26 consortia from the four fields of humanities and social sciences, engineering sciences, life sciences and natural sciences. The Text+ consortium is one of six consortia from the humanities, including Berd@NFDI, KonsortSWD, NFDI4Culture, NFDI4Memory, NFDI4Objects. While there are many cross-consortia activities via the NFDI sections, the Text+ consortium is in particularly close dialogue with the humanities and social sciences consortia.
Showcase
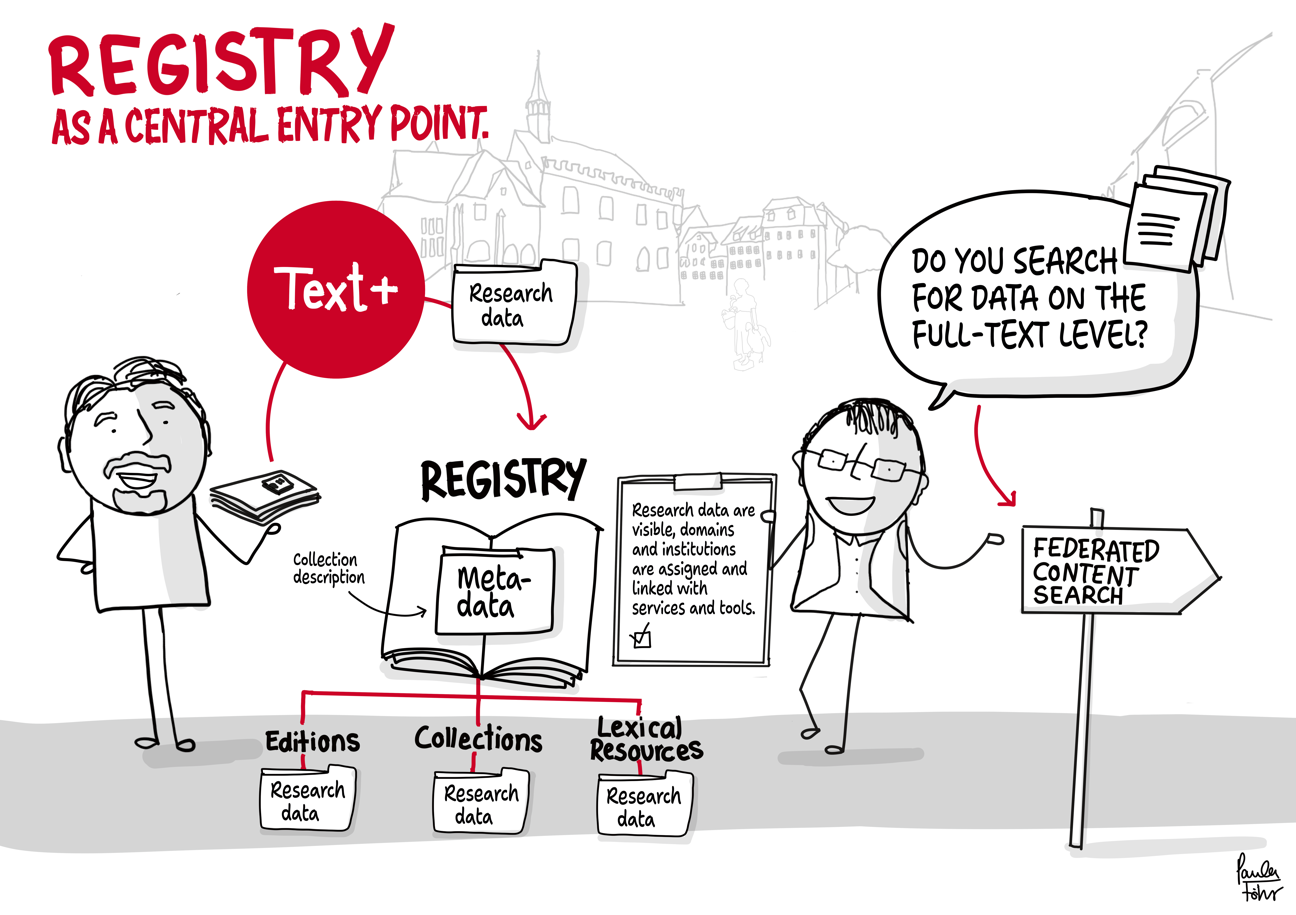
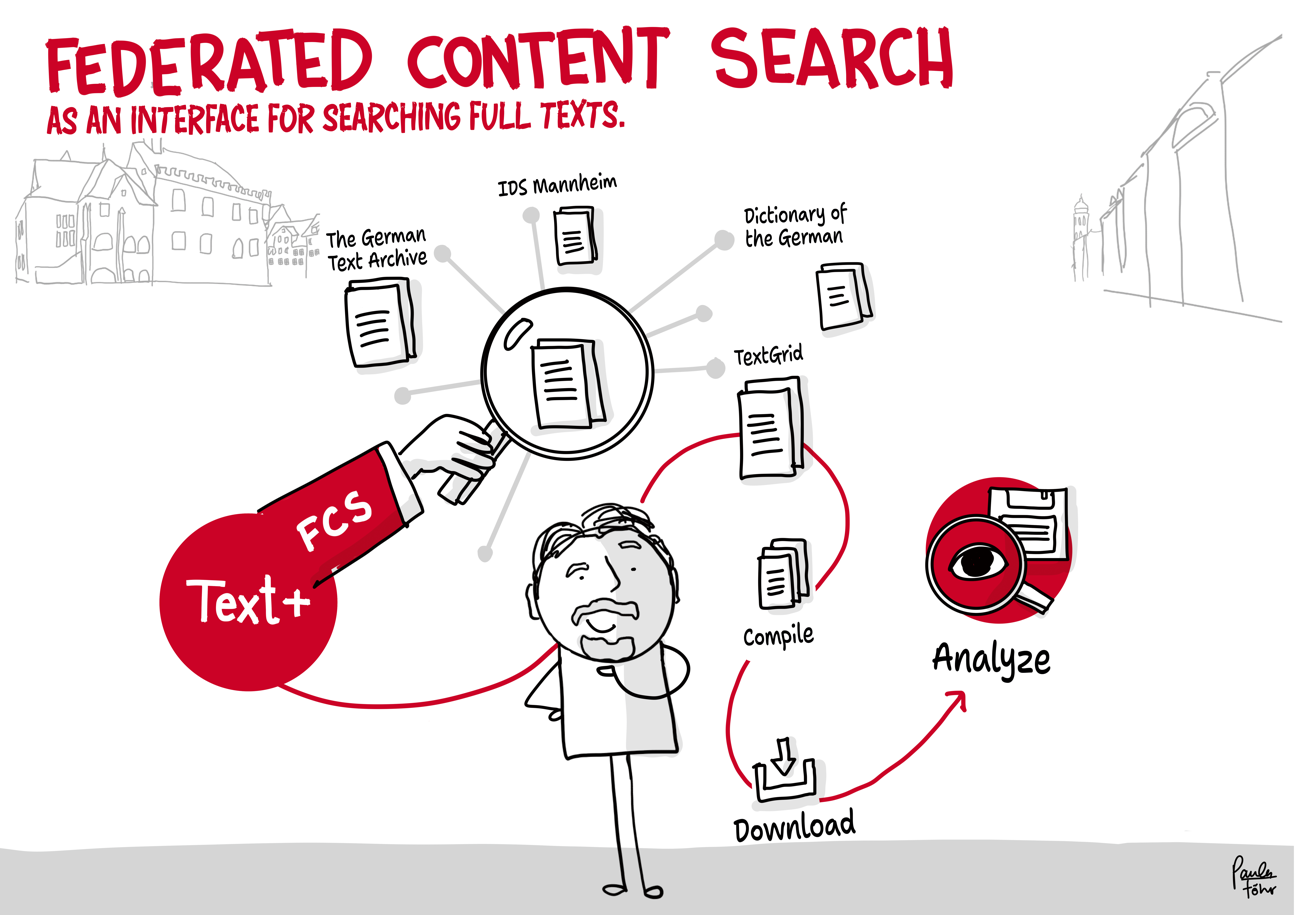
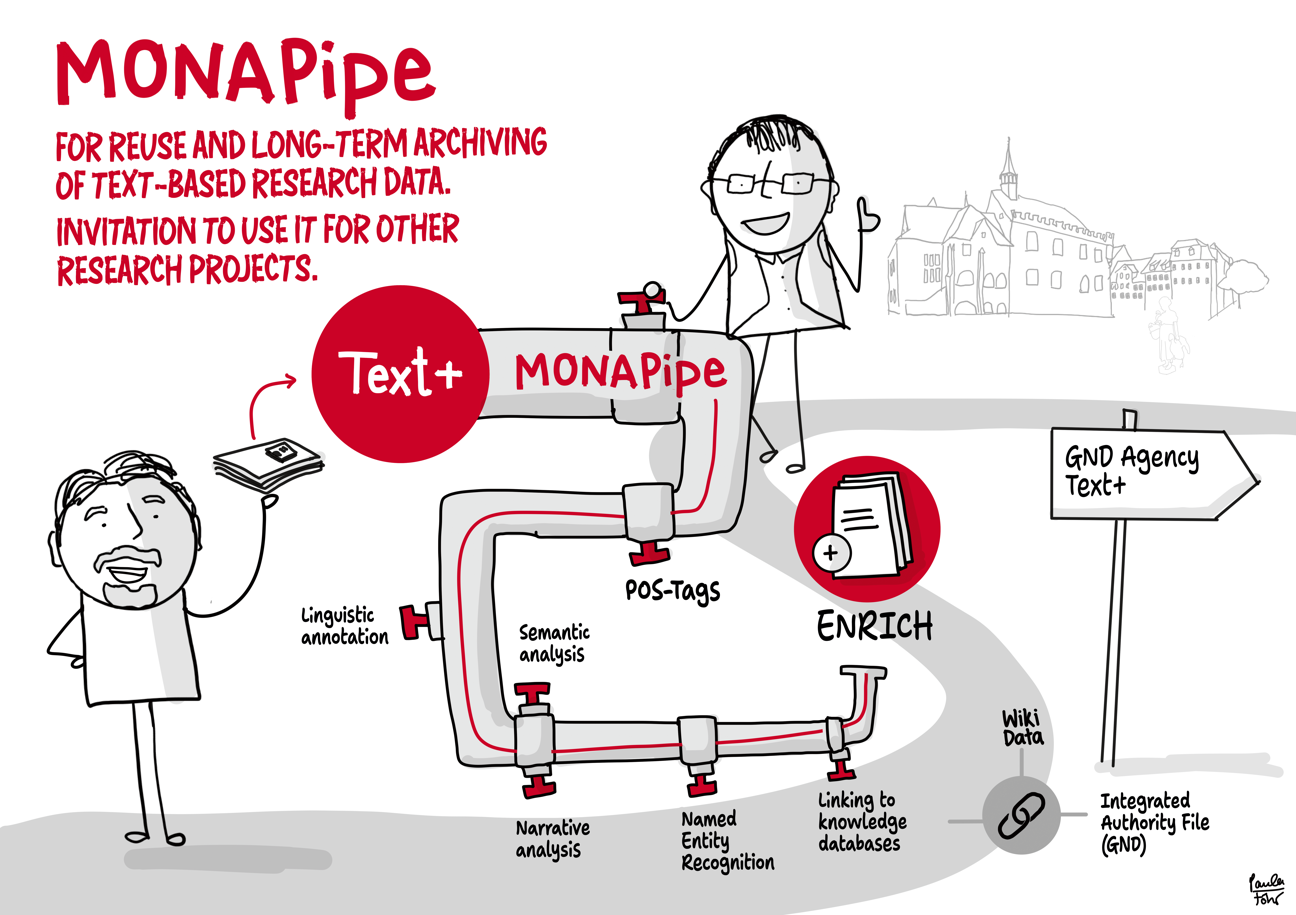
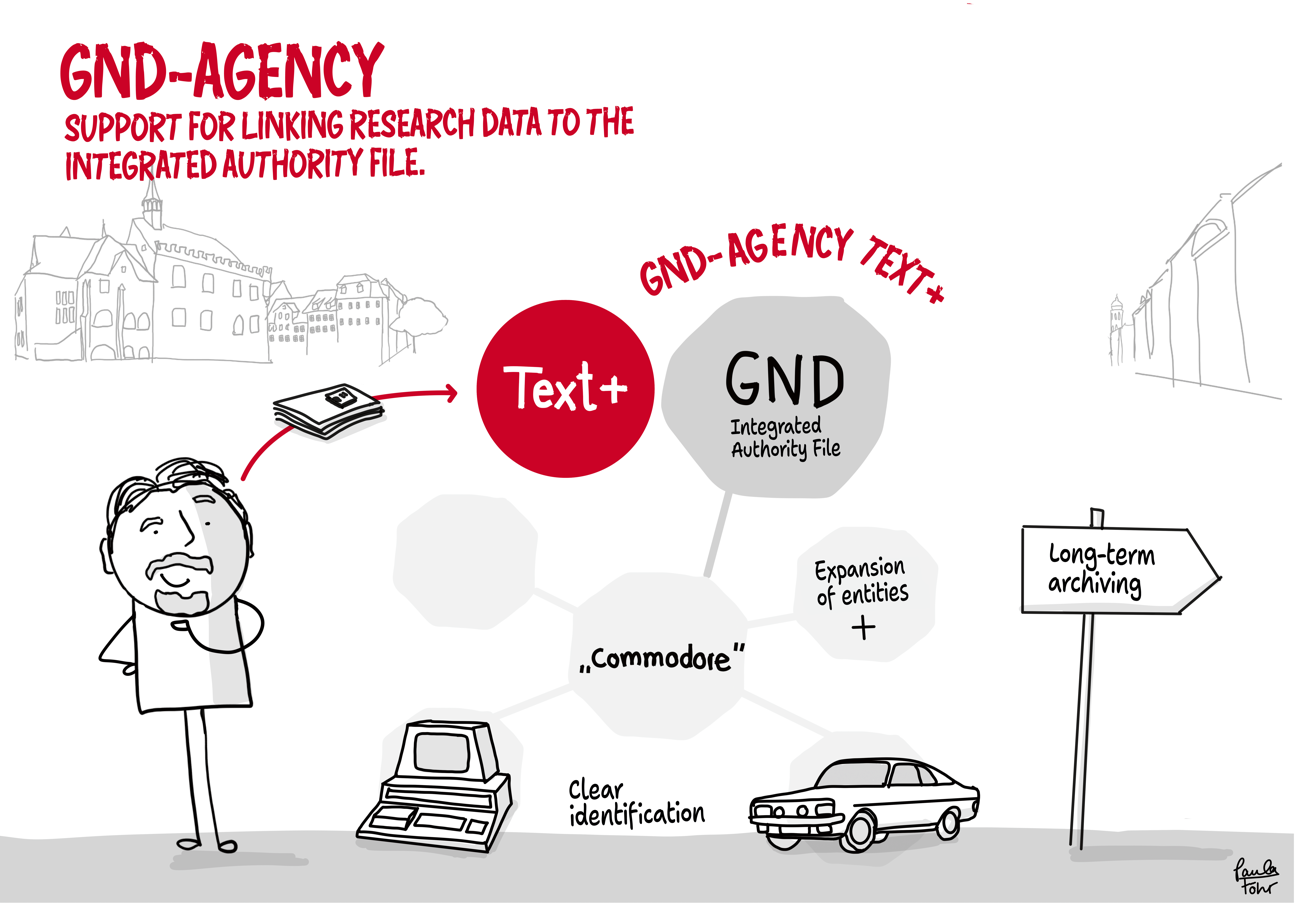
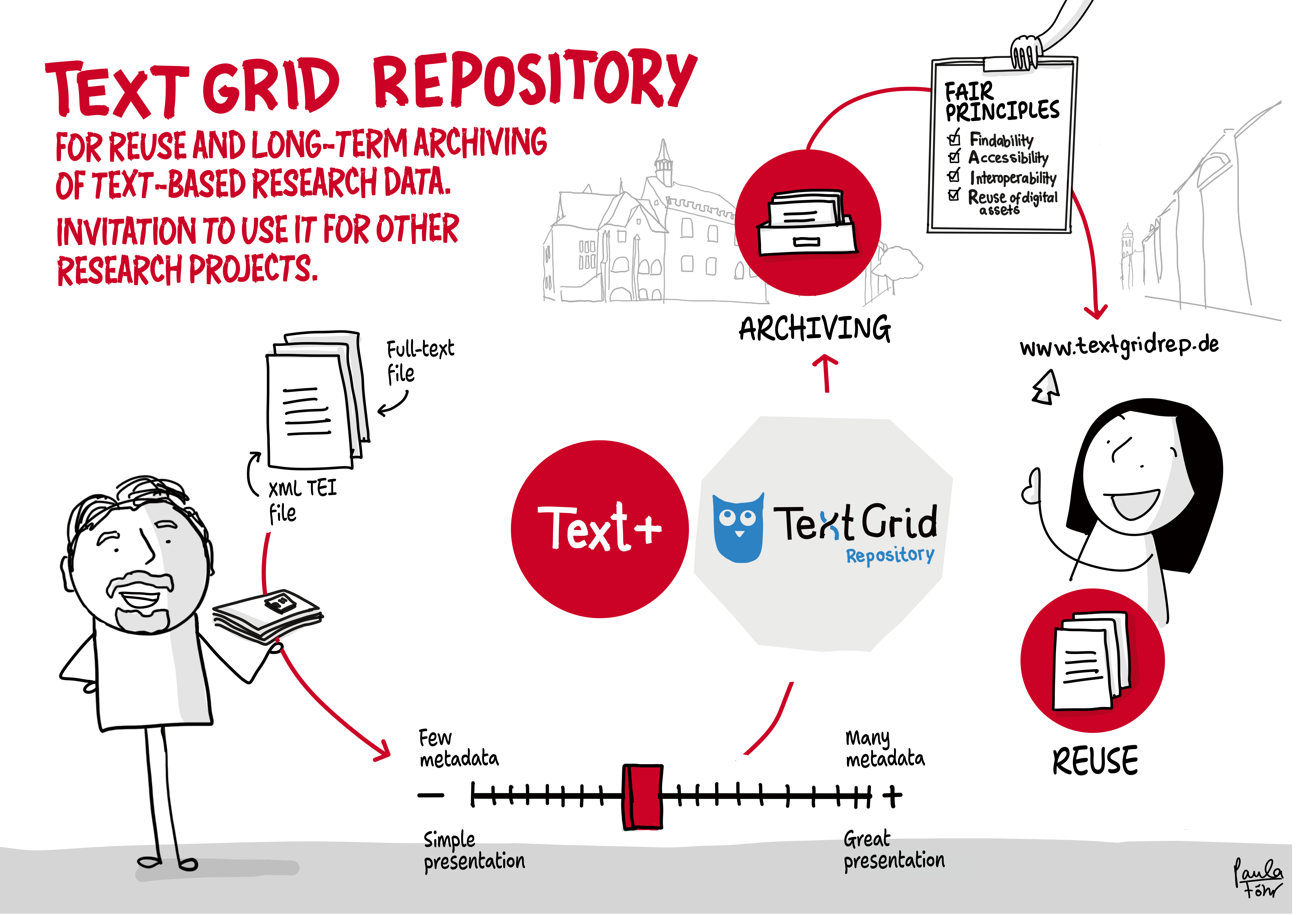
Using the example of the transfer of research data stored on discs, the outlined workflow provides an impression of data integration in Text+. It ranges from initial contact and consulting to the integration, re-utilisation and long-term preservation of the data (registry, FCS, MonaPipe, GND agency, TextGrid repository).